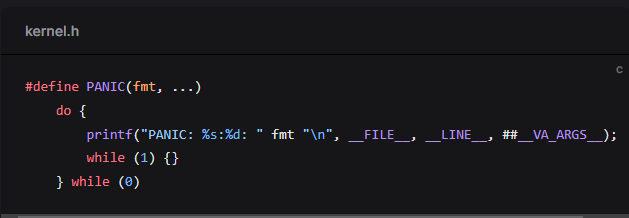
Intro
We have some basic capabilities in our supervisor now and we can turn our attention to user applications. We can already run multiple independent processes with their own registers and stack. We need a few more features to be able to run user applications as processes within our OS.
Firstly we need a virtual address mechanism so that each process/application can have an address space. The same virtual addresses can be used in multiple applications but these will map to different physical addresses so that applications dont interfere with each other.
Secondly we need a mechanism for creating and running user applications. Our applications will be written in C and the compiled executables will be loaded at the same time as the kernel.
Finally we need the ability to switch between supervisor mode and user mode so that applications dont have the capability to interfere with each other or the kernel.
Virtual Memory

0x0000-0000 to 0xffff-ffff each program can have a 4GB virtual address space. The physical address space may be much smaller.
Processor hardware (not the Operating Syestem) provides the ability to translate virtual addresses to physical addresses.

Memory is divided into 4KB pages. Virtual addresses are mapped to physical memory using a two level page table.
The first level page table contains 1024 4 byte entries pointing to upto 1024 second level pages.
This structure allows upto 1024x1024= 1M pages which equates to 4GB virtual memory.
If the kernel+data starts at 0x8000-0000 and is 2MB in size the first level page table will just have the 512th entry completed pointing to a single second level page containing entries for 2048 data pages.
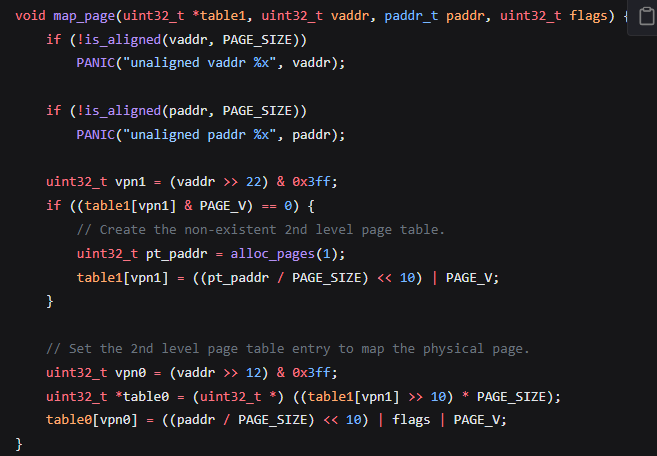
In this way Page Table nodes are setup for each page in a process.

When we create a process we must map all the kernel pages into the table so that they can be accessed by the process.
We must also put the pointer to the start of the page table into our process structure.

Note that the sfence instructions ensure that writing the new satp is completed as a single operation without interruption.
Application


Finally the kernel is build, including shell.bin.o which is our application.
Run Application In User Mode
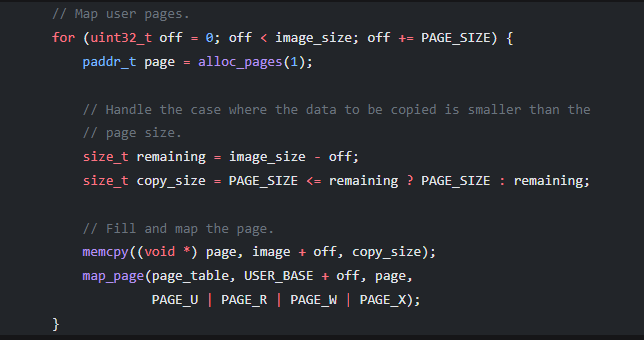
Now we have the program we want to run appended to the kernel, we can create a process by allocating memory for the program, copying the program into the memory pages and adding page table entries. The jiggery pokery in the build script gives us the information we need regarding the program location within the kernel. We now have a process containing our application ready to run.

System Calls



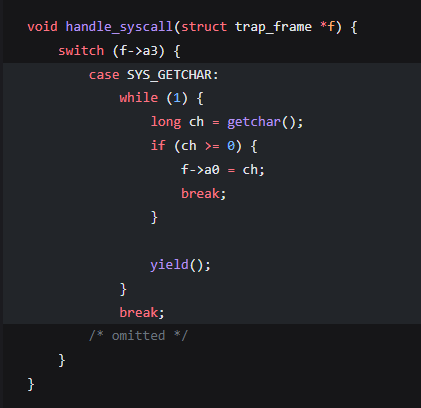
By checking CSRs handle_trap determines that an ecall is responsible for the exception and invokes handle_syscall.

User Shell


Outro

It gives you a nice warm feeling to be able to execute commands from the shell, even though they are very basic.
- QEMU provides a pretty realistic RISC-V environment for investigations. It needs openSBI to initialise the "virtual hardware" for us.
- openSBI is another level of software to consider, it runs in M-mode (machine) and does all the hardware specific (memory, interfaces, peripherals) initialisation for us.
- openSBI calls allow programs running in S-mode (supervisor) to use hardware functions such as writing to the console.
- We can write our Operating System in C. The occasional assembly language instructions we need to use for privileged instructions and initialisation can easily be specified using inline assembler.
- Our OS could use the C standard library.
- Our OS is running in S-mode and can access CSRs (Control and Status Registers) to find the cause and type of exceptions and other information.
- We define two areas of storage for a stack and free memory. We allocate memory in 4096 byte pages.
- A process has its own stack and memory. We move between processes using a context switch.
- RISC-V hardware converts virtual to physical addresses based on a two level page table.
- Switching to user mode protects the kernel and isolates processes from each other. It is simple to implement.
- We can easily write a user shell to allow us to use basic functions